
Ce chapitre va sans doute bousculer un peu le protocole. Vous risquez à la fin de vous dire que je ne l’aime pas, que finalement c’est du bas de gamme tout juste bon à reléguer au musée … C’est faux ! RIP est un très bon protocole, il sera capable de couvrir encore de nombreux besoins actuels et on pourra très bien le mettre en œuvre sur de grands et beaux réseaux. Mais pour bien l’utiliser il est important de savoir ce qu’il peut faire et où sont ses limites !
RIP ! Tu comptes à l’infini !
Dans le chapitre précédent, une subtilité aura sans doute échappé aux moins aguerris d’entre-vous ! En effet, nous sommes parti du postulat que tous les routeurs émettaient leurs updates en même temps ! Quelle erreur ! Certes, ils émettent leurs updates toutes les 30 secondes, mais le t0 de départ peut très bien être décalé d’un routeur à un autre, ne serait-ce que parce que vous ne les aurez pas mis sous tension tous exactement au même moment !
Nous savons que RIP considère qu’une route ayant un coût supérieur à 15, soit donc 16 sauts, est inutilisable. En conséquence un routeur transmet une information d’inaccessibilité en affectant un coût de 16 à une route.
Enfin, sachez qu’un routeur inscrit une route en Possibly Down lorsqu’il reçoit une information d’inaccessibilité pour cette route. Ces concepts seront expliqués dans le paragraphe suivant.
Dans notre réseau exemple (désormais habituel), en situation nominale, 10.0.0.0 est connu :
- de R2 et R3 en 1 sauts via R1
- de R4 en 2 sauts via R2
- de R1 comme directement raccordé à son interface E0.
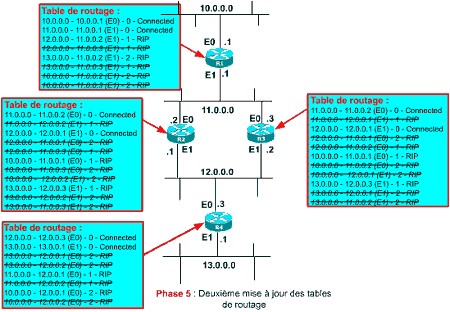
Examinons le comportement du protocole si R1 transmet à R2 et R3 une information d’inaccessiblité (coût de 16) pour le réseau 10.0.0.0 (son interface E0 étant par exemple HS) :
- Tout d’abord R1 émet un update : à réception de l’update de R1, R2 et R3 mettent à jour leurs tables pour la route 10.0.0.0 en lui affectant un coût de 16. En effet, dans leurs tables c’était R1 qui contrôlait le coût de la route vers 10.0.0.0. Comme R1 a modifié son coût, R2 et R3 s’alignent sur le nouveau coût.
- Puis R4, 15 secondes plus tard, émet son update : R2 et R3 reçoivent de R4 une information selon laquelle 10.0.0.0 est connu de R4 en 2 sauts ! Ce coût étant meilleur que celui de 16 annoncé par R1, R2 et R3 incrémentent de 1 le coût annoncé par R4 et initialisent une nouvelle route pour 10.0.0.0 via R4 en 3 sauts !
- Puis, 5 secondes après R4, R2 et R3 émettent un update : R4 et R1 reçoivent donc une information selon laquelle ils peuvent atteindre 10.0.0.0 en 3 sauts. Donc R1 prend cette information pour argent comptant et initialise une entrée dans sa table pour 10.0.0.0 via R2 en 4 sauts (il choisi ici R2 mais aurait pu choisir R3 !). R4, quand à lui, va modifier le coût de sa route pour 10.0.0.0 en 4 sauts. En effet, c’est R2 qui contrôle le coût de sa route pour 10.0.0.0 !!
- Dans un update suivant, R4 renverra à R2 et R3 un coût de 4 pour 10.0.0.0. Ceux-ci enregistreront la modification de coût et afficheront 5 pour cette route puisque c’est R4 qui contrôle le coût de route …
Il y aura donc ainsi un rebond entre R2-R3 et R4 jusqu’à ce que la route atteigne un coût de 16 et soit donc déclarée inaccessible dans tous les routeurs ! C’est ce que l’on appelle le Count to Infinity (comptage à l’infini !). L’animation suivante démontre qu’il faudra environ au total 19 échanges d’updates, répartis sur 4 minutes 30 secondes environ, entre R2-R3, R1 et R4 pour que le réseau 10.0.0.0 soit bien déclaré inaccessible dans tous les routeurs !
Il était difficile de schématiser le processus précédemment décrit sur des images fixes ou même en gif animé. Je vous propose donc cette petite animation au format YouTube ! . Il s’agit d’une ancienne animation Flash convertie en vidéo, le bouton Pause à l’intérieur de la vidéo ne fonctionne donc plus mais vous pouvez utiliser les fonctionnalités du lecteur YouTube pour stopper l’animation si elle est trop rapide.
Avouons que ce n’est pas un fonctionnement optimum ! Le plus grave est que si du trafic pour 10.0.0.0 est émis dans le réseau, il va rebondir entre R2-R3 et R4 jusqu’à ce que les tables de routages soient bien alignées ! Cependant, à cause de ces rebonds, la charge des routeurs va monter en flèche jusqu’à éventuellement les rendre hors service ou, pour le moins, bloquer l’acheminement de tout le trafic. Or, dans ce trafic, sont incorporés les updates qui doivent justement mettre à jour ces tables ! Le délai de mise à jour sera d’autant plus long et au final vous aurez un réseau partiellement HS !
Rassurez-vous, les concepteurs du protocole ont bien vu le problème (ils ne sont pas neu-neu tout de même !). Dans notre exemple, le problème vient du fait que R4 envoie une information à R2 et R3 d’une route potentiellement meilleure pour 10.0.0.0 ! Or la route pour 10.0.0.0 de R4 passe par R2-R3 ! Pourquoi donc informer R2 et R3 ? Il n’y a aucune raison valable …
Plus généralement un routeur ne devrait pas réémettre une information de route à un routeur par qui il l’a apprise ! Si R4 ne parle pas de 10.0.0.0 à R2 et R3, il n’y aura pas de comptage à l’infini ! R2 et R3 ne remplacerons pas la route 10.0.0.0 via R1 ayant un coût de 16 par une fausse route via R4 ayant un coût de 3 !
Il existe deux solutions possibles :
-
la première est que les routeurs ne réémettent pas les informations sur les interfaces par lesquelles ils les ont apprises. Cette technique s’appelle le split horizon (ne me demandez pas pourquoi !).
-
la deuxième est que les routeurs réémettent les informations sur les interfaces par lesquelles ils les ont apprises, mais en leur affectant un coût de 16. Cette technique s’appelle le poison reverse (ne me demandez pas pourquoi non plus !).
Selon les implémentations du protocole par les différents constructeurs de routeurs on pourra trouver une méthode ou l’autre pour combattre le « count to infinity ». Chez Cisco, à priori, le poison reverse a la préférence, mais par un jeu de commande on peut cependant activer le split horizon. Sincèrement je ne vois pas l’intérêt du « poison reverse » ! Il augmente la taille des updates sans apparemment aucune raison ! Je serai donc tenté de préférer le « split horizon » ! Si l’un d’entre-vous à un exemple qui permette de clairement favoriser le poison reverse, je suis à son écoute …
L’animation suivante, vous présente donc le même scénario de mise à jour des tables de routage que précédemment mais en implémentant le « split horizon » :
Vous aurez remarqué en fin d’animation que les routeurs attendent 2 minutes avant de supprimer le réseau 10.0.0.0 de leurs tables de routage. Ce phénomène est expliqué dans le paragraphe suivant.
Convergence ! Que tu es lente …
La convergence est la capacité du protocole à réaligner toutes les tables de routage lors d’un changement d’état dans le réseau. Ce changement peut être de natures diverses : lien d’interconnexion ou routeur HS, interface de routeur HS, ajout ou suppression d’un réseau IP ou d’un site, etc. Quel qu’il soit, ce changement implique une modification des déclarations des réseaux dans les différentes tables de routage. Selon la nature du changement le protocole aura un comportement différent. Pour comprendre pourquoi je dis que la convergence est lente, il faut comprendre ce qui se passe en cas de modification de la configuration du réseau. C’est le but des paragraphes suivants.
Le cas du support Hors Service
Si un support (un lien d’interconnexion ou un LAN) est détecté HS (dans le cas du LAN ce n’est pas vraiment évident, mais admettons !) :
- tous les routeurs directement raccordés au support détectent physiquement (perte de porteuse ou de signal électrique généralement) sa perte.
- ils modifient l’état du réseau IP correspondant dans leur table de routage et le mettent en Possibly Down (Peut-être HS) puis ils envoient l’information aux autres routeurs au prochain update (30 secondes plus tard !) en plaçant le coût de la route à 16 !
- ils attendent ensuite pendant l’équivalent de 4 updates (2 minutes) avant de considérer réellement le réseau HS
- si au bout de ces 2 minutes le réseau support n’est pas revenu à la normale, ils valident une éventuelle route secondaire ignorée lors de précédents updates car présentant un coût plus important que la route nominale.
- si le réseau remonte avant 2 minutes, le routeur d’accès valide de nouveau la route initiale, replace son coût à 0, et réenvoie l’information de coût 0 à tous ses voisins dans le prochain update !
Le pire c’est que ça continue, encore ! Lorsqu’un routeur reçoit une information selon laquelle une destination est inaccessible (coût de 16), il passe le réseau en Possibly Down (coût de 16) dans sa table, transmets l’information aux autres au prochain update et attend également 2 minutes avant de valider une potentielle nouvelle route.
Au final, si vous sommez les délais d’émission d’updates qui obligent à attendre au minimum 30 secondes avant de transmettre l’information aux voisins, avec le délai d’attente de 2 minutes qui est décalé d’au minimum 30 secondes d’un routeur à l’autre à cause du délai de retransmission des updates, c’est long ! Un petit calcul sur notre réseau exemple :
Supposons que le réseau 10.0.0.0 passe HS juste après émission d’un update où il était déclaré valide. Ce moment sera appelé t0.
- R1 déclare 10.0.0.0 Possibly Down dans sa table de routage et enclenche son timer (pour information ce timer est appelé : Hold-time timer, quand une route est suspendu elle est placé dans le Garbage Collection, ne me demandait pas pourquoi un nom si barbare !)
- A t0+30″, R1 informe R2 et R3 que 10.0.0.0 est inaccessible en plaçant un coût de 16 dans l’update
- R2 et R3 placent le réseau 10.0.0.0 Possibly Down à t0+30″ dans leur table et enclenchent leurs timers
- A t0+60″, R2 et R3 informent R4 que 10.0.0.0 est HS.
- R4 déclare 10.0.0.0 Possibly Down et enclenche donc son timer (il est t0+60″)
- A t0 + 2′, R1 pourrait valider une nouvelle route éventuelle (s’il en existait une ! Ce qui n’est pas le cas dans notre exemple !). Il diffusera cette route au prochain update vers R2 et R3. Ceux-ci n’en tiendront pas compte car ils sont toujours en Garbage Collection pour cette destination.
- R2 et R3 valideront cette éventuelle nouvelle route annoncée par R1 à t0 + 2’30 », puis transmettront l’update de mise à jour à R4 que lui-même ne validera qu’à t0+3′.
Bref ! Si votre réseau aligne 10 routeurs sur une route, il faudra au minimum 2’+(10*30″) = 7 minutes pour réaligner vos tables ! Bon courage ! Vous avez dit délai de convergence long ?
Le cas du routeur Hors Service
Si un routeur est HS le cas est différent, car cette fois-ci il n’y a pas de déclaration d’inaccessibilité par un coût de 16 dans un update ! Le problème est que les voisins du routeur ne reçoivent plus d’update de ce routeur ! Certaines routes ne sont donc plus annoncées ! Les routeurs voisins n’ont aucun moyen de savoir si un pair est HS car aucune connexion n’est établie entre eux. C’est l’absence de mise à jour (on parle de rafraîchissement des tables) des routes précédemment annoncées qui déclenchera la mise à jour.
Chaque routeur, je l’ai indiqué précédemment, enclenche un timer lorsqu’il initialise une entrée contenue dans un update. Chaque fois que cette entrée est de nouveau annoncée par un update, le timer est remis à 0. Si le timer n’est pas raffraichi pendant 6 updates consécutifs (3 minutes), la destination est déclarée Possibly Down comme précédemment.
Toujours comme précédemment, le routeur garde cette route dans l’état Possibly Down pendant 2 minutes (4 updates) avant de la déclarer réellement HS et de valider une éventuelle route de secours.
Dans notre réseau exemple, si R1 passe hors tension ou rencontre un problème logiciel qui le rend inopérant, le réseau 10.0.0.0 n’est plus annoncé à R2 et R3. Ceux-ci attendront donc 5 minutes (3 minutes + 2 minutes) avant de déclarer le réseau HS dans leurs tables. Mais ils informeront R4 du problème par un coût de 16 sur la route 10.0.0.0 quand la destination sera passée en Possibly Down dans leurs tables, soit donc au bout de 3 minutes ! Dans le détail, supposons que R1 passe HS juste après avoir émis un update normal à R2 et R3. Ce moment sera appelé t0 :
- R2 et R3 ne reçoivent donc plus d’updates de R1 ensuite.
- R2 et R3 déclare 10.0.0.0 Possibly Down dans leur table de routage à t0+3′ (6 updates plus tard) et enclenchent leurs hold-time timers.
- A t0+3’30 », R2 et R3 informe R4 que 10.0.0.0 est inaccessible en plaçant un coût de 16 dans l’update à destination de R4.
- R4 placent donc le réseau 10.0.0.0 Possibly Down à t0+3’30 » (à réception de l’update de R2 et R3) dans sa table et enclenchent son hold-time timer.
- A t0+5′, R2 et R3 n’ayant pas reçu de nouvel update pour 10.0.0.0 suppriment la route de leurs tables de routage et ne l’émettent plus vers R4.
- R4 ne recevant plus d’updates contenant 10.0.0.0 de la part de R2 et R3, supprime 10.0.0.0 de sa table à t0+5’30 ».
Donc, comme précédemment, si votre réseau aligne 10 routeurs sur une route, il faudra au minimum 5’+(10*30″) = 10 minutes pour réaligner vos tables ! Encore une fois on peut dire que RIP n’est pas un modèle de rapidité !
Pourquoi ?
J’en vois qui se grattent la tête ! Mais pourquoi attendre 2 minutes dans un cas ou 5 minutes dans un autre avant de valider une nouvelle route ? Pour au moins deux raisons :
- Pour ne pas mettre en péril la stabilité du réseau ! Si chaque fois qu’il y a une micro-coupure sur un support les routeurs entamaient une reconfiguration immédiate du réseau nous aurions des tables de routage qui joueraient au yo-yo !!
- Pour laisser le temps aux routeurs voisins de bloquer leurs tables pour la destination indisponible. Car si on ne temporisait pas la reconfiguration on risquerait d’obtenir des boucles de routage dans le réseau, ce qui n’est franchement pas bien !
Croyez-moi sur parole, il vaut mieux prendre un peu de temps pour rien que de mettre l’ensemble du réseau par terre !!
RIP ! Tu ne me dis pas tout …
RIP v1 pose un petit problème que la v2 a heureusement résolu ! RIP v1 ne transmet pas les masques des réseaux qu’il annonce dans ses updates. Dis comme ça, cela paraît anodin, mais croyez-moi ça ne l’est pas ! Explication …
Un cas qui marche …
Supposons que pour économiser des adresses réseaux vous mettiez en place sur votre réseau d’entreprise un plan d’adressage IP formé de sous-réseaux. Par exemple, comme dans 90% des cas, vous allez utiliser le réseau 10.0.0.0 qui est non routable internet (RFC1918) pour définir votre plan d’adressage (Pour ceux qui sont déjà largués, je vous invite à revoir l’Excellent Chapitre 7 du cours IP.)
 Supposons que vous ayez défini le plan d’adressage ci-contre.
Supposons que vous ayez défini le plan d’adressage ci-contre.
Vous remarquez que tous les réseaux physiques sont associés à la même adresse de classe A : 10.0.0.0. Celle-ci est divisée en sous-réseau par le masque 255.255.0.0 qui lui est attribué. Ainsi on a pu créer les sous-réseau 10.1.0.0/16 à 10.4.0.0/16 chacun d’eux étant affecté à un réseau physique.
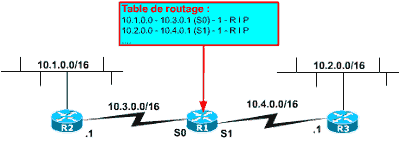 La table de routage du routeur R1 est dans ce cas telle que ci-contre.
La table de routage du routeur R1 est dans ce cas telle que ci-contre.
Les sous-réseaux 10.1.0.0 et 10.2.0.0 sont bien routés. R2 et R3 ont chacun émis un update comportant l’adresse 10.1.0.0 (pour R2) et 10.2.0.0 (pour R3) vers R1. Cet update ne comportait pas de masques des adresses réseaux mais R1 ayant les pieds dans les sous-réseaux 10.3.0.0 et 10.4.0.0 a appliqué le masque associé à ces adresses. Les entrées sont donc correctes.
Un cas qui ne marche pas …
Maintenant, supposons que vous ayez un plan d’adressage un peu différent. Supposons que vos liens d’interconnexions utilisent une autre adresse réseau que celles employées sur les LANs (croyez-moi, c’est très courant !).
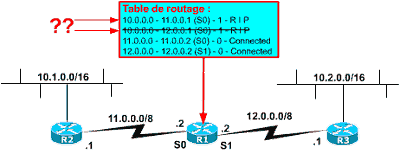 Vous pourriez avoir l’adressage ci-contre.
Vous pourriez avoir l’adressage ci-contre.
Les liens d’interconnexions utilisent les adresses 11.0.0.0 et 12.0.0.0 (science-fiction, mais bref …), par contre les deux LANs conservent l’adressage en 10.1.0.0/16 et 10.2.0.0/16. Les updates émis ne comportant pas les masques associés aux adresses réseaux, R1 ne peut pas interpréter le nombre de bits définissant la partie réseaux et sous-réseaux dans l’adresse. Tout ce qu’il sait, c’est qu’un réseau ayant la valeur 10 en premier octet est un réseau de classe A. Et i lsait que les réseaux de classe A utilise le premier octet comme octet réseau. Il en déduit que R2 donne accès au réseau 10.0.0.0 avec un coût de 1. Mais R3 lui envoie un update similaire ! Comme les deux updates ont le même coût, il fait un choix. Ici la route par R2 est préférée à celle par R3.
Est ce grave ? OUI !! Depuis R1 ou R2 essayez donc d’envoyer des données vers une station sur 10.2.0.0/16 et vous m’en direz des nouvelles !
Un cas qui aurait pu marcher !
OK ! Donc le problème vient du fait que R1 n’a pas les pieds dans le réseau 10.0.0.0 ? Qu’à cela ne tienne ! Ajoutons lui un LAN dans le réseau 10.0.0.0 comme ci-dessous :
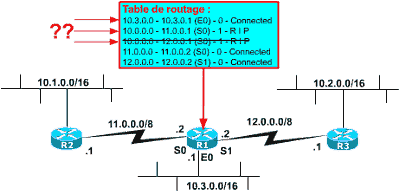 On pourrait penser que cela suffirait, car maintenant R1 peut appliquer le masque qui est affecté à l’adresse IP de son interface E0 (masque 16). Mais non ! C’était trop simple ! Parce qu’en vérité R2 ne l’informe pas dans son update d’un sous-réseau 10.1.0.0 mais d’un réseau 10.0.0.0. La même chose pour R3 ! Pourquoi ? Parce que l’update est émis sur un numéro de réseau différent du numéro de réseau annoncé. Autrement dit :
On pourrait penser que cela suffirait, car maintenant R1 peut appliquer le masque qui est affecté à l’adresse IP de son interface E0 (masque 16). Mais non ! C’était trop simple ! Parce qu’en vérité R2 ne l’informe pas dans son update d’un sous-réseau 10.1.0.0 mais d’un réseau 10.0.0.0. La même chose pour R3 ! Pourquoi ? Parce que l’update est émis sur un numéro de réseau différent du numéro de réseau annoncé. Autrement dit :
- si R1 émet un update pour 10.1.0.0 sur un réseau 10.0.0.0 il envoie bien la valeur 10.1.0.0, partant du principe que le routeur distant pourra appliquer son masque sur l’update puisqu’il est également dans le réseau 10.0.0.0.
- si R1 émet un update pour 10.1.0.0 sur un réseau différent (11.0.0.0 par exemple), il envoie la valeur 10.0.0.0 partant du principe que le routeur distant ne peut comprendre la partie sous-réseau puisqu’il n’a pas les pieds dans le réseau 10.0.0.0.
Donc la table de routage de R1 fait un choix entre les deux annonces 10.0.0.0 de R2 et R3. Ici elle choisie une route par R2. Par contre R1 garde un route distincte pour 10.3.0.0 car le réseau lui est directement accessible sur son interface E0. En bref, encore une fois le sous-réseau 10.2.0.0 est inaccessible depuis R1 et R2.
Enfin … Un cas qui aurait pu ne pas marcher !
Dans l’exemple suivant, il n’y a pas de problème ! Le routage vers les sous-réseaux 10.2.0.0 et 10.3.0.0 est correct, pourtant R1 n’a pas les pieds dans le réseau 10.0.0.0 !
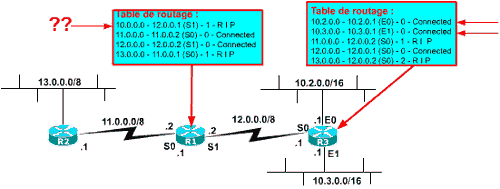 Certes ! Mais tous les sous-réseaux du réseau 10.0.0.0 sont accessibles par un seule et même interface de R1 (interface S1). Donc tous ce qui concerne le réseau 10.0.0.0 en général est émis par R1 vers R3. Comme R3 a les pieds dans le réseau 10.0.0.0 et contrôlent les sous-réseaux 10.2.0.0 et 10.3.0.0 il sait assurer le routage également. Enfin le LAN de R2 est en dehors du réseau 10.0.0.0 donc il n’y a plus de problèmes.
Certes ! Mais tous les sous-réseaux du réseau 10.0.0.0 sont accessibles par un seule et même interface de R1 (interface S1). Donc tous ce qui concerne le réseau 10.0.0.0 en général est émis par R1 vers R3. Comme R3 a les pieds dans le réseau 10.0.0.0 et contrôlent les sous-réseaux 10.2.0.0 et 10.3.0.0 il sait assurer le routage également. Enfin le LAN de R2 est en dehors du réseau 10.0.0.0 donc il n’y a plus de problèmes.
Bilan ?
Si vous utilisez RIP v1, méfiance !! La façon la plus intelligente de définir son plan d’adressage quand on utilise RIP v1 est le dernier cas ! Il permet de diminuer le nombre de routes dans les tables de routage en condensant (on dit en agrégeant !) automatiquement les définitions de sous-réseau, sans nuire au routage. Les autres cas sont à proscrire !
Rassurez-vous, RIP v2 a levé ces limitations car il transmet dans ses updates les masques de sous-réseaux. Cette fonction est devenue nécessaire à partir du moment où l’on a commencé à utiliser le VLMS (Variable Length Masque Subnet) qui permet de définir pour un même réseau des longueurs de masques différentes. Mais c’est une autre histoire …
Conclusion
Il apparaît maintenant clairement que RIP a de sérieuses limites. Implémenter ce protocole sur de grands réseaux nécessite d’y regarder à deux fois ! La limite des 15 routeurs maximum sur une route, le délai de convergence long, l’émission des tables de routages complètes sur le réseau toutes les 30 secondes et l’impossibilité de router des sous-réseaux en version 1, ne militent pas vraiment en sa faveur !
Mais relativisons … RIP a été pendant longtemps le seul protocole de routage interne vraiment correctement implémenté par les constructeurs de routeurs et garantissant surtout une bonne interopérabilité entre les différentes marques de routeurs. On le trouve encore dans beaucoup de réseaux et on l’implémente encore sur des réseaux de petites envergures ou pour assurer des fonctions simples (pour les experts : vérification de la présence d’un routeur au bout d’un tunnel IP ne proposant pas de keepalive, par exemple). RIP n’est pas mort, j’en prendrai pour exemple le fait qu’à ma connaissance les serveurs UNIX ne reconnaissent que RIP comme protocole de routage ou que lorsqu’on veut relayer des informations de routage entre deux routeurs de marques différentes ont choisi RIP. Alors ne l’enterrez pas tout de suite !
Mais aujourd’hui, il y a plus rapide, plus beau, plus fort, plus top quoi ! Il y a OSPF ! Mais attention, c’est réservé aux grands, aux beaux réseaux, sinon c’est du gachis ! Dans le chapitre suivant, je vous propose donc une petite présentation « ligth » d’OSPF !